Preview
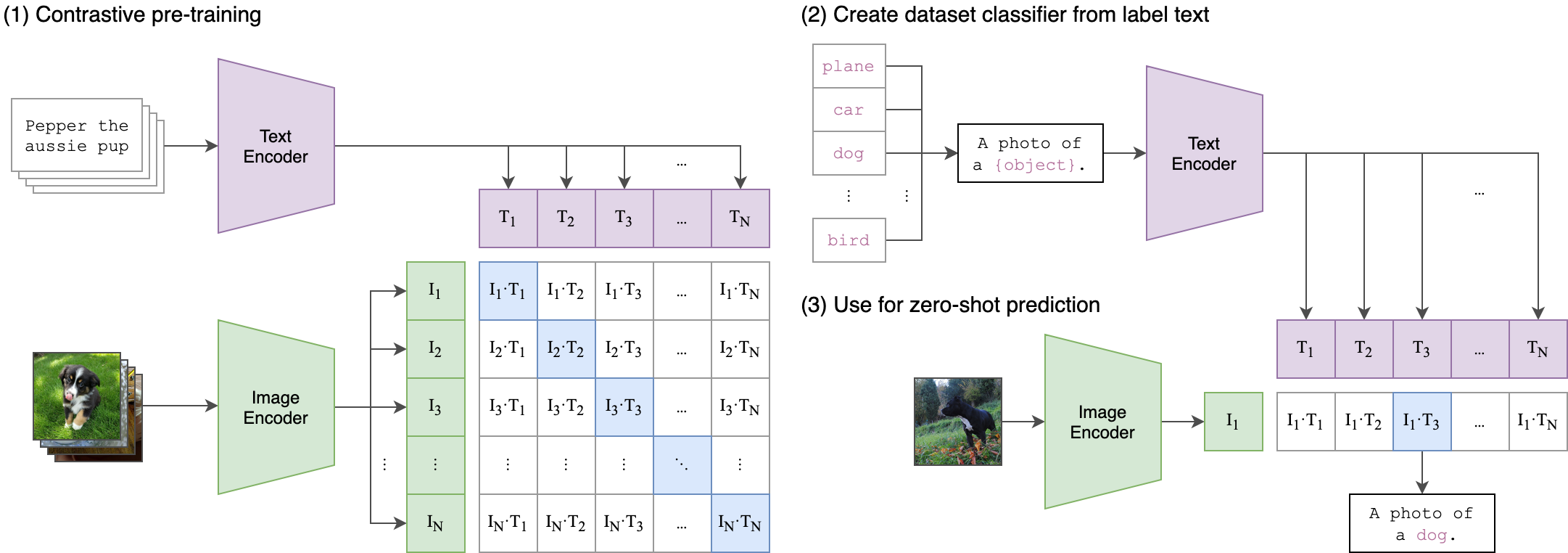
CLIP is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image classification. CLIP uses a ViT like transformer to get visual features and a causal language model to get the text features. Both the text and visual features are then projected to a latent space with identical dimension. The dot product between the projected image and text features is then used as a similar score.
Milestone
We merged a feature #858 to the main branch of hcaptcha-challenger on October 22, 2023 to handle CAPTCHA via the CLIP image-text cross-modal model.
Previously, we trained and used the ResNet model to handle the image classification challenge. The model network parameters are so small that our exported ResNet ONNX model is only 294KB and we can still get over 80% correct in the binary classification task. This is more than enough for a CAPTCHA challenge with only nine images.
But today, in 2023, there are so many key breakthroughs in Computer Vision that we can easily lift the accuracy to 98%+ on such simple tasks from the CAPTCHA😮.
Thus, we also designed a factory workflow based on this, i.e., using the same network model design, but training models for different prompt scenarios on different batches of image data.
Although these small models can only handle binary classification tasks with a single target, we trade off an extreme performance experience, i.e., we go from training to iterating a model version in just a few minutes.
Automatic image annotation
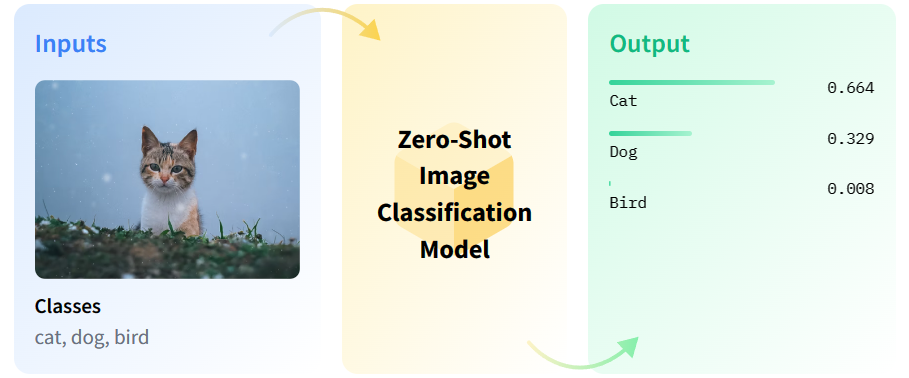
Zero shot image classification is the task of classifying previously unseen classes during training of a model.
We have been using CLIP in the factory workflow for automatic image annotation tasks since 2022, and at that time, the accuracy of the best CLIP model in dealing with zero-shot image classification was not satisfactory, but it was very useful for saving your time.
If I chose to manually categorize 1k images, it would probably take me at least 10 minutes and my nerves would be high the whole time. Oh and at the same time you're going to need a processing environment that's just right or you're going to have a very slow process.
With CLIP, the same process takes 3 minutes. I only need to pay extremely little attention to samples that are misclassified or have low scores.

It may seem like a bit of a contradiction in terms. But if you've had this experience, you should know the difficulty of multi-categorizing a bunch of cluttered images is quite different for human attention than identifying outliers in a bunch of images with similar overall characteristics.
Dilemmas and breakthroughs
At the time, we were only running CLIP on a local GPU server. we tried to run it on edge terminals and open up the inference interface, but how to export CLIP to ONNX and run inference tasks on terminals that don't rely on pytorch and GPUs?
This question stumped me. So much so that as projects like clip-as-service started to gain traction in the industry, we tried the next best thing, which was to assume that there were enough devices in the edge network to run the CLIP model.🥹
Note that you don't need much configuration to run the CLIP model, in the case of RN50.openai you only need up to 500MB of RAM to run it, and we're just comparing it here to ResNet (294KB) from the previous section. That is, if we choose to design the CLIP model as a hot-swappable component, we can't possibly require players using this program to be ready to download a 500MB model and read it frequently at any time.
With breakthroughs in computer vision research around the world, pre-trained models that score increasingly well are starting to emerge. ↪️benchmarks
- CLIP supports zero-shot image classification with prompts. Given an image, you can prompt the CLIP model with a natural language query like "a picture of ". The expectation is to get the category label as the answer.
- OWL-ViT allows zero-shot object detection conditional on language and one-shot object detection conditional on image. This means that you can detect objects in a single image even if the underlying model didn't learn to detect them during training! You can refer to this notebook to learn more.
- CLIPSeg supports zero-shot image segmentation conditional on language and one-shot image segmentation conditional on image. This means you can segment objects in a single image even if the underlying model didn't learn to segment them during training! You can refer to this blog post that illustrates this idea. GroupViT also supports zero-shot segmentation.
- X-CLIP Demonstrates zero-shot generalization to video. To be precise, it supports zero-shot video classification. Check out this notebook for more details.
At the same time, the higher the model's score, the larger its number of parameters usually is and the more memory it takes up. This also predisposes CLIP to be a model better suited to deal with decision-based tasks, where it is relatively too slow to respond. The fastest open-source CLIP models available with just the right number of parameters still don't process fast enough on the CPU.
In the case of the CAPTCHA, deploying and using CLIP on user endpoints seems anachronistic. This is because for CAPTCHA, the challenges involving the CV and NLP parts do not yet fully utilize the strengths of the cross-modal model. It is clear that the CLIP model is a performance overflow for CAPTCHA available worldwide.
That is, it specializes in a combination of abilities we don't yet need, but for which it can do things, we have better options in the moment.
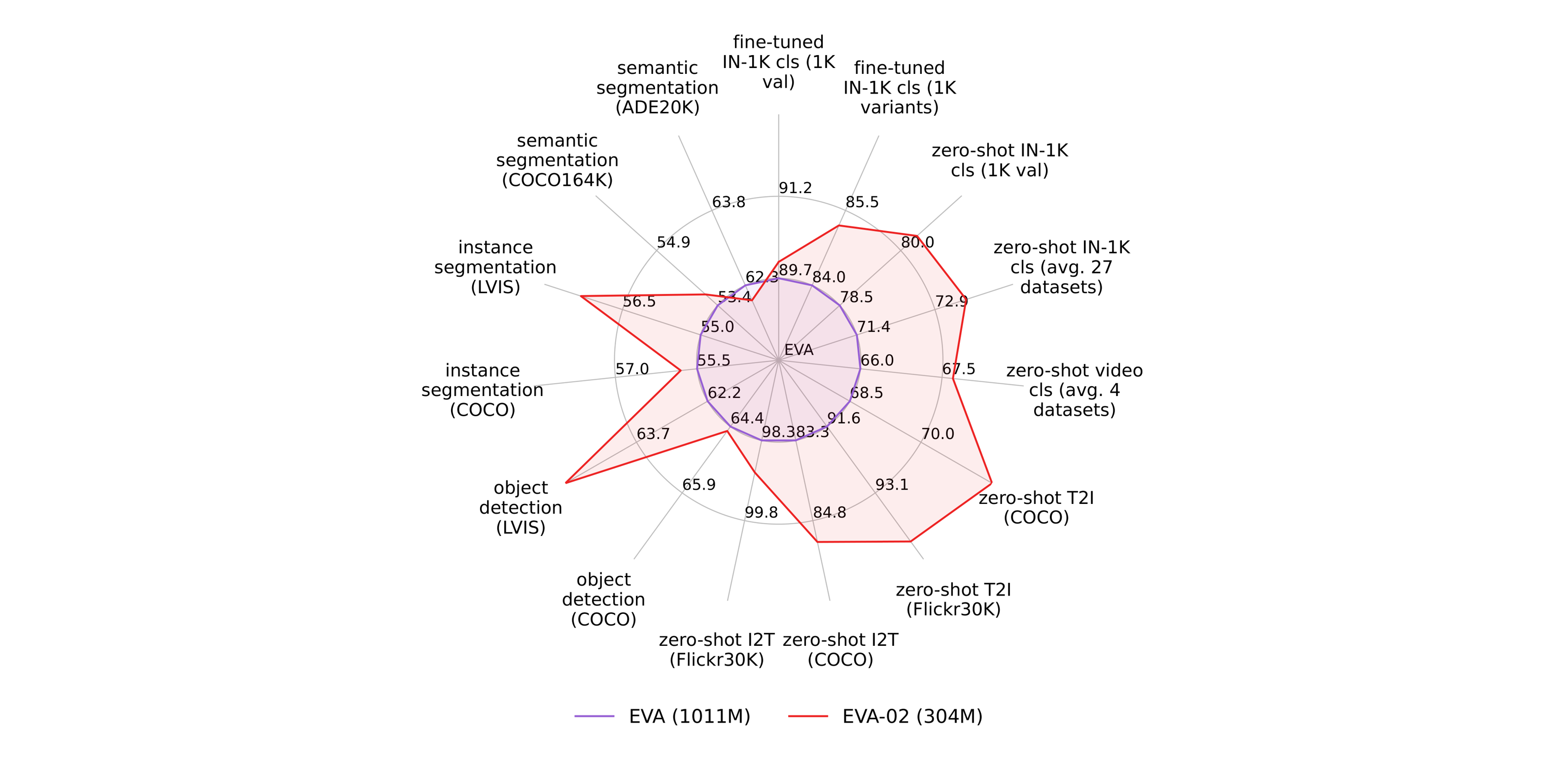
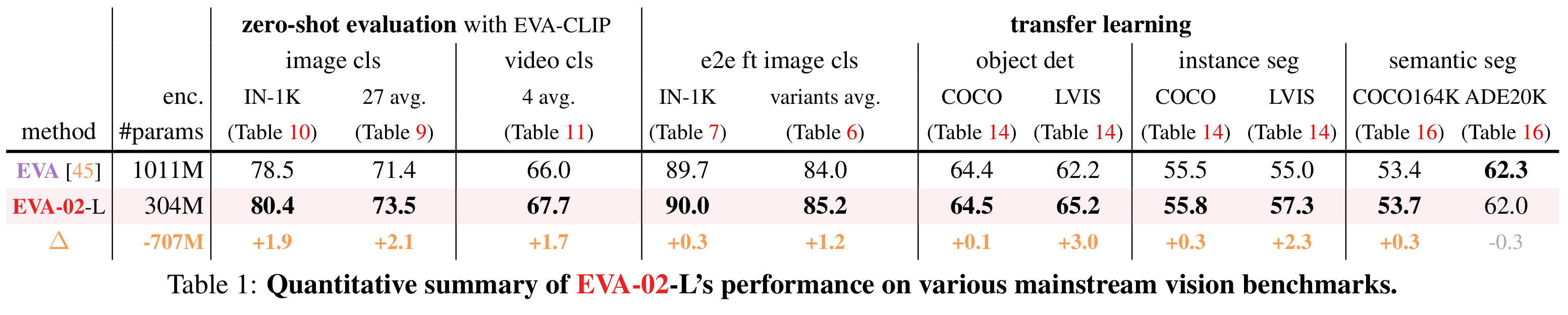
It is entirely possible to opt for more targeted solutions, such as the use of small-volume models (e.g. mobilenetv3 and EVA-02) that are only valid for a specific task, but have an accuracy rate that far exceeds that of CLIP. ↪️benchmarks
Scenarios for the CLIP-ONNX
As we mentioned earlier, for the automatic image annotation and remote service scenarios, we don't need to export the model to ONNX, and we should instead make full use of the GPU (if available) to improve performance.
It is an inevitable trend that model parameters are getting larger and larger. So based on the present and looking to the future, what are the possible application scenarios for CLIP-ONNX?
🚧
The generation of the LLM
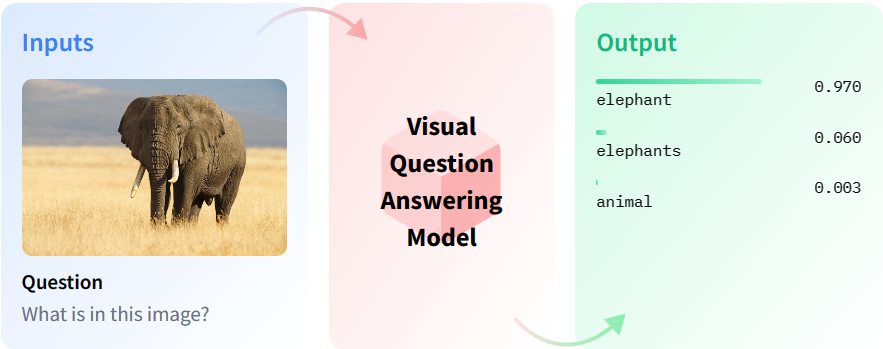
Visual Question Answering
Visual Question Answering is the task of answering open-ended questions based on an image. They output natural language responses to natural language questions.
LLM OpenAgents
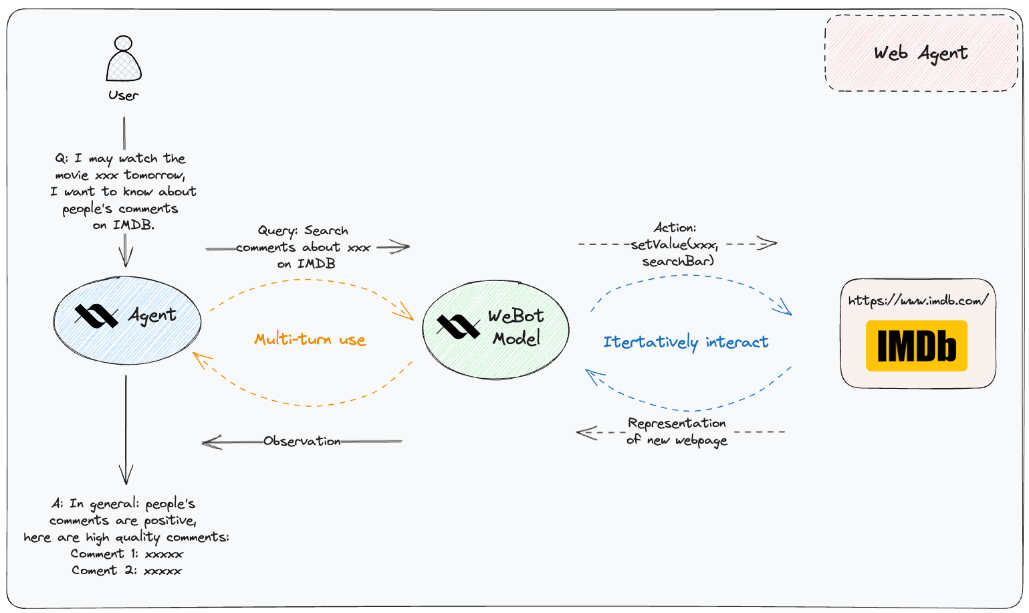
XLang Agents are Large Language Model-powered(LLM-powered) Agents, aiming to utilize a range of tools to enhance their capabilities, serving as user-centric intelligent agents. Currently, the XLang Agents supports three different agents focusing on different application scenarios, including:
- Data Agent: The Data Agent is equipped with data-related tools, allowing it to efficiently search, handle and manipulate and visualize data. It is proficient in writing and executing code, enabling various data-related tasks.
- Plugins Agent: The Plugins Agent boasts integration with over 200 plugins from third-party sources. These plugins are carefully selected to cater to various aspects of your daily life scenarios. By leveraging these plugins, the agent can assist you with a wide range of tasks and activities.
- Web Agent: The Web Agent harnesses the power of a chrome extension to navigate and explore websites automatically. This agent streamlines the web browsing experience, making it easier for you to find relevant information, access desired resources, and so on.